La semaine dernière, un document interne de Google a fuité suite à sa découverte et à son partage par un référenceur Erfan Azimi, et tous les consultants SEO du monde en parlent en boucle depuis. Il faut dire que cela donne accès à de nombreux éléments qui pourraient être intégrés dans l’algorithme actuel du moteur de recherche.
Les données qui ont été partagées listent en effet des dizaines et des dizaines de critères techniques, avec à chaque fois des informations qui expliquent rapidement ces derniers ainsi que leur format. Certains référenceurs parlent de cette fuite comme de la meilleure chose qui soit arrivé dans le monde du SEO. D’autres s’insurgent sur le fait que Google nous ait menti sur certains sujets (alors qu’on avait déjà eu de nombreuses fois la preuve de ces mensonges de la part du moteur de recherche, notamment via certains "officiels" de chez Google comme John Mueller).
Voyons cela en détails.
Des informations SEO à prendre avec précaution !
Avant tout, faites attention ! Tout ce qui est écrit dans cet article (ou dans les articles de mes confrères) est une interprétation de documents internes de Google. En aucun cas cela ne nous permet d’affirmer certains éléments avec certitude, ceci pour plusieurs raisons :
- Cela ne nous donne pas le poids de chaque élément au sein de l’algorithme global. Si par exemple dans un article on vous dit que ce critère a beaucoup d'importance, c’est faux : rien ne permet d’en être sûr. Cela pourrait tout autant avoir très peu d'importance ;
- Rien ne nous indique si Google a modifié ou va modifier certains de ces éléments ;
- Attention aussi aux surinterprétations qui sont faites : très souvent, les descriptifs sont assez obscurs et peuvent parfois être mal interprétés ;
- Les documents parlent aussi de Youtube, de Google Lens ou d’autres services de la firme américaine. Ce n’est donc pas uniquement lié au référencement naturel ;
- Les documents n’indiquent pas non plus si ce sont des éléments de tests, des éléments actuellement utilisés partout, ou des critères utilisés dans certains cas de figure (par exemple dans des phases de tests ou dans des thématiques bien précises).
La seule chose que l’on peut affirmer, c’est que ce document nous donne à minima un ordre d’idée des éléments sur lesquels Google travaille (ou sur lesquels il a travaillé ou travaillera bientôt).
Que contient cette fuite de données ?
Parmi les articles qui en parlent déjà, certains points sont passés un peu sous les radars, tandis que d'autres étaient en réalité déjà connus depuis longtemps (certains depuis des années). Voici donc ce qu'il ne fallait pas rater sur cette fuite de données, et commençons en premier lieu par ce que l'on savait déjà (à moins de vivre dans une grotte)
Google Chrome n’est pas toujours votre ami
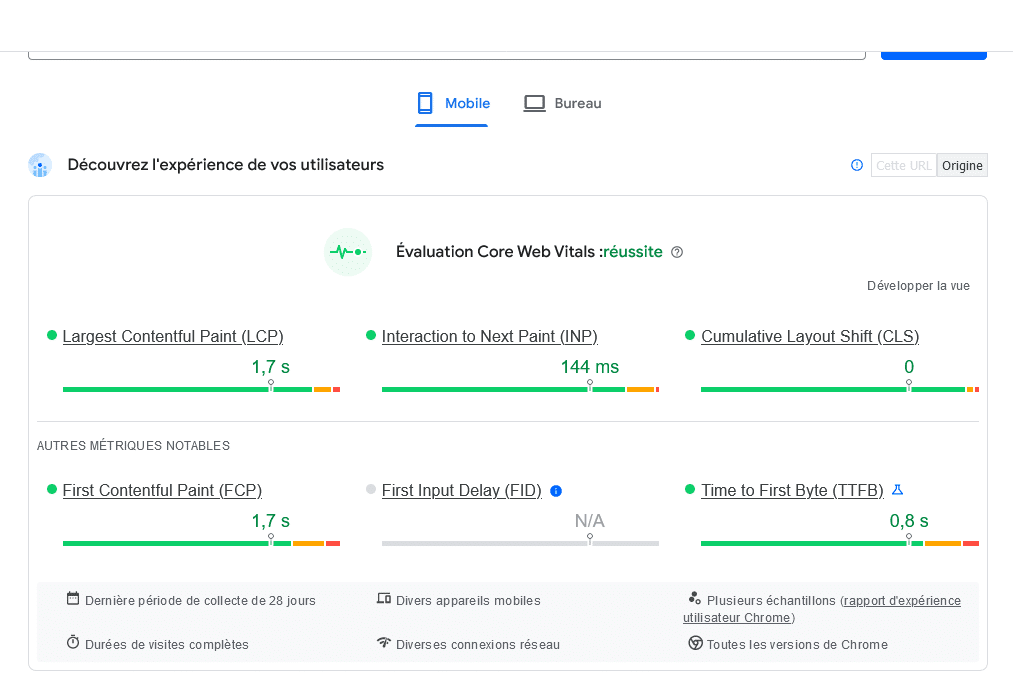
De nombreux éléments dans ces documents indiquent l’utilisation des données du navigateur Google Chrome, notamment les pages visitées et le temps passé dessus.
Ici, il n’y a rien de surprenant : on savait déjà que le moteur de recherche récupérait tout un tas de données soit directement dans son moteur lui-même, soit via son navigateur Google Chrome. C’est par exemple le cas depuis des années avec les informations liées au temps de chargement. Ce sont en effet des données utilisateurs qui définissent si votre page est considérée comme « lente », « à améliorer » ou « rapide ».
Les interactions des internautes et NavBoost
En fin d’année dernière, lors de son procès Antitrust, les équipes de Google avaient été obligées d’affirmer publiquement qu’ils utilisaient bel et bien les interactions des utilisateurs, notamment les clics sur les résultats (et le comportement de l'internaute une fois arrivé sur le site final). C’était la première fois que l’on a réellement entendu parler de Navboost.
Cette partie de l’algorithme permet à Google de « réajuster » les résultats en fonction des clics des différents utilisateurs (en se basant sur les données des utilisateurs des 13 derniers mois). En d’autres termes, plus les internautes vont cliquer sur un résultat, plus ce dernier va gagner en visibilité.
Impossible par contre de mesurer l’importance de ce critère par rapport aux autres (même si certains tests de référenceurs l'ont déjà démontré). Ce qui est intéressant par contre, c’est que le document donne plus de détails. En premier lieu, Google classerait les clics des utilisateurs en trois types :
- Le clic « écrasé », qui serait ignoré ;
- Le clic court : l’internaute clique un résultat mais n’y reste pas « longtemps » ;
- Le clic long (et qualitatif) : l’internaute clique sur un résultat et reste dessus plus longtemps.
Cela voudrait donc dire que, non seulement il faudrait obtenir des clics sur nos résultats pour les faire monter, mais que en plus il faudrait s’assurer qu’ils poursuivent leur navigation pendant un minimum de temps.
Autre élément mis en avant dans cette fuite de données, c’est que les données de Chrome sont aussi utilisées par Google pour déterminer les contenus populaires d’un site pour ensuite les ajouter dans les Sitelinks (ces « sous-liens » du résultat principal d’un site)

D’ailleurs, l’utilisation des actions de l’internaute n’est pas nouvelle en soi. Depuis longtemps, Google a déposé des brevets en ce sens, comme celui-ci qui permettrait potentiellement au moteur de recherche de proposer à l’internaute lors de sa recherche initiale des résultats issus d’une seconde recherche (quand un grand nombre d’internautes réaffinent leur recherche initiale, et donc qu’ils ne trouvent pas les résultats initiaux pertinents).
Tous les sites ne sont pas égaux
Cela aussi, on le savait déjà : Google utilise bel et bien des listes blanches pour certaines thématiques (ce qui vous favorise donc énormément dans les recherches si vous en faites partie). Il le fait par exemple dans le domaine de la santé (notamment avec le COVID). Rien de neuf sous le soleil donc.
Les liens
Concernant les liens, il y a plusieurs choses intéressantes. Tout d’abord, Google classerait les liens en 3 groupes de « qualité » :
- Basse ;
- Moyenne ;
- Forte.
Ceux en catégorie basse seraient ignorés, et ceux en catégorie haute auraient bien plus d’impact. On s’en doutait, et c’est d’ailleurs une classification logique pour un moteur de recherche. Mais le document n'indique malheureusement pas selon quels critères précis les liens sont classés dans ces catégories.
Par contre, les documents dévoilés donnent d’autres informations sur ce qui pourrait être utilisé par Google. Par exemple, un lien est aussi classé selon un « SourceType », qui détermine la « qualité » de la page d’origine du lien. Là aussi, rien d’étonnant en soi si Google juge aussi la pertinence de la page qui vous fait un lien (si on est logique, le SourceType serait logiquement utilisé pour classé les liens dans les groupes de qualité).
Deux autres points ont attiré mon attention concernant les liens :
- Un attribut « fontsize » qui vérifierait la taille du lien (ce qui permet de supposer que Google veut juger s'il s'agit d'un vrai lien utilisable par l’internaute ou s’il est trop « petit » pour avoir de l’importance) ;
- Un attribut « CreationDate » qui enregistre la date de première découverte d’un lien et la dernière date connue où ce lien a été trouvé. Un lien présent depuis longtemps pourrait avoir donc plus de poids.
L’indexation
Il y a aussi beaucoup d’informations concernant l’indexation. On retrouve sans surprise le « PagerankScore », qui déterminerait donc la « popularité » d’une URL.
Mais on trouve notamment d’autres données intéressantes concernant chaque URL :
- Le « PriorSignal » qui donne des informations concernant l’historique de l’URL (théoriquement, si la page était « mauvaise » avant, Google pourrait ne pas vouloir revenir dessus) ;
- L’URLHistory qui détaille le fait que Google garde en mémoire les 20 derniers changements d’une URL. Attention, c’est très dur de savoir dans quelle mesure chaque ancienne version est utilisée ou non dans l’indexation. On peut cependant supposer que cela peut impacter cette dernière en cas de changement trop importants d’une même URL (par exemple en réutilisant des noms de domaines expirés et en les modifiant trop fortement ou trop rapidement).
Les contenus, entités et auteurs
Pour ce qui est des contenus eux-mêmes, on retrouve différentes informations concernant leurs analyses.
Il existe le concept de « SalientTermSet », qui liste le poids des thématiques abordés par une URL (sous forme d’unigrams et de bigram). Pour un moteur de recherche, supprimer le « bruit » pour faire ressortir les principaux sujets d’un contenu est tout simplement logique. Mais ce que nous indique le détail de « SalientTermSet », c’est que Google ferait ressortir les thématiques d’un contenu en fonction de termes uniques ou de deux termes associés l’un avec l’autre. Par exemple, on pourrait avoir un Salient Term « Référencement naturel » mais pas « Référencement naturel Google ».
On retrouve aussi d'autres aspects intéresssants concernant les entités et les auteurs :
- L’attribut WebRefEntities est utilisé à la fois en indexation et pour fournir les résultats à l’internaute, et il détermine les entités nommées d’un document (une marque, une personne, un lieu, une date, etc.). Cela démontrerait l’importance de savoir les utiliser, un peu comme le conseil l’excellent outil YourTextGuru ;
- Plusieurs parties de ces documents SEO parlent aussi des auteurs, ce qui laisserait à penser que Google cherche à attribuer systématiquement un auteur pour chaque contenu indexé, sans doute dans une optique de mesure de la qualité ou de la pertinence. D’ailleurs, on retrouve d’autres champs « author » plus précis, par exemple des champs liés aux conversations de blog ou forum (avec notamment l’attribut AuthorName dans « BlogsearchConversationNode »).
Les noms de domaine
Là aussi, plusieurs choses sont intéressantes en ce qui concerne les noms de domaine. Il existe tout d’abord un attribut « hostAge » pour chaque contenu, et qui indique la date où Google a découvert pour la première fois un contenu sur le nom de domaine concerné, permettant de mieux séparer le spam dans un « bac à sable » : « These data are used in twiddler to sandbox fresh spam in serving time ». En d’autres termes, un site récent pourrait être bien plus facilement écarté par Google lors de l’indexation.
Il existe aussi un attribut de qualité appelé « SiteAuthority » qui jugerait donc la crédibilité d’un site entier, en d'autres termes cela ressemble à une note globale de qualité attribuée à un nom de domaine. Google a pourtant toujours affirmé qu'un tel critère n'existait pas.
Enfin, le fait que Google pourrait aussi déprécier les « Exact Match Domain » (EMD) semble aussi être vrai avec l’attribut de qualité « exact_match_domain_demotion ». Pour rappel, un EMD est un nom de domaine qui contient le mot clé principal, par exemple « kayak-pas-cher.fr ». Là encore, il est impossible de savoir à quel point cette dépréciation pourrait avoir de l’impact ou non.
La thématique du site
Si on parle des sujets abordés par un contenu, il y a de vraies pépites dans ces documents de Google. Il y a notamment un attribut « siteFocusScore » qui détermine à quel point un site est spécialisé dans un domaine, et ensuite un attribut SiteRadius qui détermine pour chaque contenu l’éloignement par rapport à ce premier score. En d’autres termes, cela pourrait vouloir dire qu’un contenu trop éloigné de la thématique d’un site spécialisé pourrait être jugé moins qualitatif. C’est d’ailleurs un constat que l’on a eu sur des prospects à l’agence : ils ont élargit leurs thématiques et ont malheureusement vu leur trafic baisser.
On constate aussi dans ces documents que certaines thématiques peuvent avoir des parties de l’algorithme qui leurs sont dédiées, par exemple avec :
- La santé (« ymylHealthScore ») ;
- L’actualité (« ymylNewsScore ») ;
- La science (« ScienceCitationAuthor ») ;
- Etc.
Cela confirme donc bien ce que l’on constate dans notre travail de référencement naturel : les mêmes actions n’ont pas toujours le même impact en fonction de la thématique du site.
Les sources
Il existe des centaines et des centaines de pages dans ces documents, donc il reste encore beaucoup de travail à la communauté SEO pour pouvoir décoritquer tout cela.
En attendant, pour ceux et celles qui veulent aller plus loin, voici quelques liens intéressants :
- L'article où Rand Fiskin décortique une partie de cette fuite de donnée, tout en donnant le nom du référenceur qui est tombé dessus (Erffan Azimi) : https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
- Un des premiers article à dévoiler et décortiquer cette fuite de données : https://ipullrank.com/google-algo-leak ;
- Les documents en entier : https://hexdocs.pm/google_api_content_warehouse/0.4.0/api-reference.html ;
- Ici, un aute classement de la fuite de données dans un fichier Excel avec ChatGPT.

Ce qui est marrant dans cette histoire, c'est que cette fuite avait été découverte plus tôt par un autre référenceur DejanSEO mais il l'avait gardé pour lui et avait prévenu les équipes de Google.
Quelles conclusions SEO en tirer ?
Et maintenant, on fait quoi avec cela ?
En réalité, pas grand-chose.
Mon avis personnel est que cela a fait couler beaucoup d’encre alors que cela ne change que très peu les préconisations que l’on peut faire actuellement (en tout cas en ce qui nous concerne avec celles que l’on donne pour nos clients chez SeoMix ou celles de l’audit intégré de SEOKEY).
Voici cependant les enseignements que l’on peut en tirer et surtout ceux que l’on peut confirmer :
- Certaines actions SEO auront un impact sur le long terme. Par exemple, concernant les clics utilisateurs et Navboost, cela est mesuré sur 13 mois. Cela veut dire qu’une amélioration à un instant T peut potentiellement ne pas se ressentir immédiatement ;
- Google utilise les entités nommées : il faut donc bien travailler les sujets que l’on aborde dans chaque contenu et il faut mettre en avant sa marque et l’auteur dans chaque publication ;
- Pour favoriser des « clics longs » (un internaute qui clique sur votre résultat et reste sur votre site), il faut optimiser et avoir une véritable continuité entre :
- la recherche de l’internaute (et ses besoins) ;
- les métas de votre contenu (balise title et balise méta description) ;
- le contenu final en lui-même ;
- Et l’ergonomie de votre site ;
- De manière générale, sur un site donné, il faut éviter de s’éparpiller avec des thématiques trop variées ;
- Google conserve l’historique des changements d’un contenu : idéalement, il faudrait donc éviter des changements trop drastiques. Sur un rachat de nom de domaine par exemple, cela confirmerait une bonne pratique qui consiste dans un premier temps à remettre le site en ligne de façon identique, avant de progressivement le modifier ;
- La réponse aux différents besoins de l’internaute semble être, comme depuis plusieurs années, un élément déterminant. Rien ne change donc ;
- Un lien obtenu depuis longtemps sur un contenu aurait plus de poids qu’un lien ajouté à postériori ;
- Lors du lancement d’un nouveau site, pour éviter le « bac à sable », il faut théoriquement y aller doucement (peu de contenus mais des contenus de qualité), avant d’augmenter la cadence des publications ;
- Il semble aussi qu’il faut éviter les noms de domaines en « Exact Match Domain » puisqu'ils auraient un malus de base.
Et vous, vous avez vu d'autres éléments intéressants ?
Vous souhaitez aller plus loin dans votre stratégie SEO ?
Anticipez les futures évolutions de Google : contactez les experts de SeoMix et confiez-nous votre stratégie SEO !


Laisser un commentaire